Полезная денормализация - Materialized View
При проектировании отношений в реляционной базе данных обычно стараются придерживаться общепринятых форм нормализации (как минимум первых трех) для того, чтобы избежать проблем/неудобств при использований базы. Например, при игнорировании форм нормализации мы можем столкнуться с проблемой, когда у нас есть несколько источников правды - дублирование данных ведет к тому что один из источников в будущем может отличаться от другого.
Иллюстрация ситуации когда у нас есть несколько источников правды:
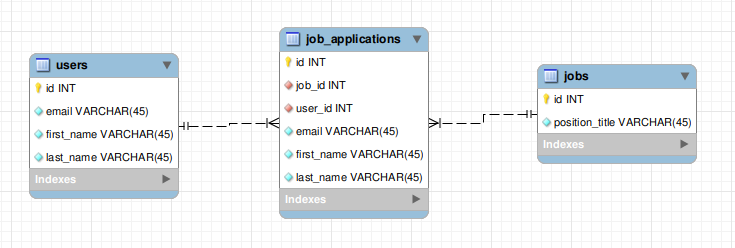
В данном случае у нас данные юзера дублируются в связующей таблице job_applications и чтобы синхронизировать эти данные между собой нам нужно писать дополнительный код.
Но в некоторых случаях нам может потребоваться денормализовать отношения/данные, чтобы ускорить SQL запрос.
контекст
- Имеется сущность
Пользователь. Некоторые пользователи могут являтьсяAдминистраторами - Имеется сущность
Вакансия - Пользователь может выбрать в профиле интересующую категорию, под-категорию и фокус (под-категория под-категории :))
- Вакансия также может принадлежать определенной категории, под-категории и иметь свои список фокусов (под-категории под-категории :))
- Администратор может запускать подбор кандидатов для каждой вакансии - проверяется совпадение категории между кандидатом и вакансией
- Администратор может заблокировать определенные категории для выбранных кандидатов - тогда данные кандидаты не будут учитываться в выборках по этим категориям.
ER-схема:
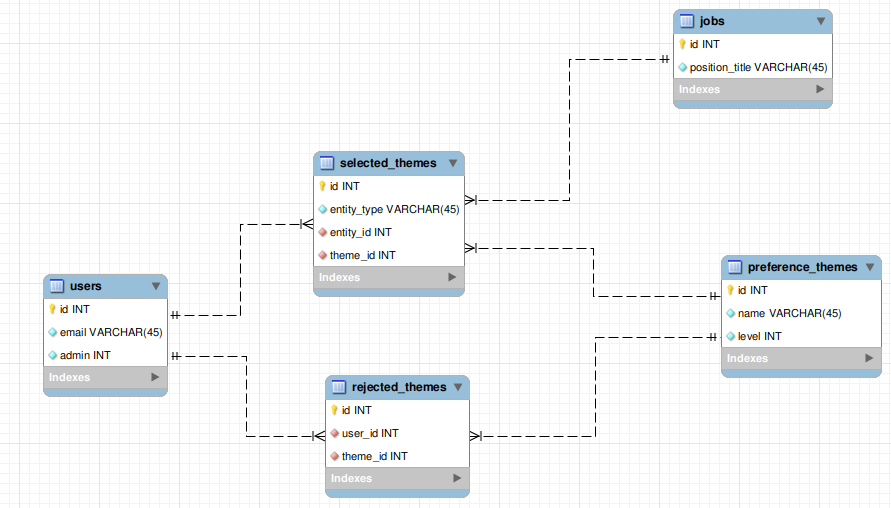
P.S.: Из-за бага в MySQL Workbench не смог указать флаг admin как BOOLEAN - пришлось оставить INT. Представьте что там BOOLEAN :)
- users - сущность пользователя
- jobs - сущность вакансии
- preference_themes - сущность категории, где level - ее уровень (0 - категория, 1 - под-категория и 2 - фокус)
- selected_themes - связующая сущность. С помощью полиморфного ключа связывает вакансии/пользователей с выбранными категориями
- rejected_themes - связующая сущность. Связывает пользователей и категории по которым будет осуществляться блокировка
Будем считать что у нас система рекомендации работает по следующему принципу:
- Мы находим тех пользователей, кто соответствует категориям указанным в вакансии
- Мы находим тех пользователей, кто заблокирован по категориям указанным в вакансии
- Возвращаем тех пользователей, кто присутствует в первой коллекции и не присутствует во второй
На данный момент нас интересует пункт 2. Предположим что интересующая нас вакансия имеет следующие категории: категория с id = 183 (level = 0), под-категория с id = 207 (level = 1) и фокус с id = 260 (level = 2).
SQL запрос для получения всех пользователей кто так или иначе заблокирован по этим категориям:
SELECT users.id
FROM users
INNER JOIN rejected_themes rt ON users.id = rt.user_id
INNER JOIN preferences_themes main_themes ON main_themes.id = rt.theme_id AND main_themes.level = 0
LEFT JOIN rejected_themes rt_sub_theme ON users.id = rt_sub_theme.user_id
LEFT JOIN preferences_themes sub_themes ON sub_themes.id = rt_sub_theme.theme_id AND sub_themes.level = 1
LEFT JOIN rejected_themes rt_focus ON users.id = rt_focus.user_id
LEFT JOIN preferences_themes focuses ON focuses.id = rt_focus.theme_id AND focuses.level = 2
WHERE main_themes.id = ANY('{183}') AND (
NOT EXISTS(
SELECT *
FROM rejected_themes
INNER JOIN preferences_themes ON preferences_themes.id = rejected_themes.theme_id AND preferences_themes.level = 1
WHERE rejected_themes.user_id = users.id
) OR sub_themes.id = ANY('{207}')) AND (
NOT EXISTS(
SELECT *
FROM rejected_themes
INNER JOIN preferences_themes ON preferences_themes.id = rejected_themes.theme_id AND preferences_themes.level = 2
WHERE rejected_themes.user_id = users.id
) OR focuses.id = ANY('{260}'))
GROUP BY users.id;Что тут вообще происходит???
Мы просто находим всех пользователей кто:
- заблокирован по категории 183
- заблокирован по категории 183 и по под-категории 207
- заблокирован по категории 183 и по под-категории 207 и по под-категории под-категории 260
Это сделано для того чтобы не блокировать пользователей, у которых блокировка создана по другой категории (например, по 183 => 207 => 262). Такой пользователь все еще имеет шанс попасть в рекомендацию потому что блокировка задана с точностью до под-категории фокуса. Но если блокировка задана с меньшей точностью - например 183 => 207, то такие пользователи должны быть заблокированы в данной выборке.
проблема
Описанный выше SQL запрос выполняется довольно часто и при этом является довольно медленным. Выхлоп EXPLAIN ANALYZE:
Planning Time: 3.382 ms
Execution Time: 11.168 ms
При этом сами блокировки для пользователей создаются довольно редко (всего около 100 штук было создано за 5 месяцев)
решение
Решающий фактор в пользу денормализации запроса и использования Materialized View:
- сущности, используемые в запросе изменяются редко (100 раз за 5 месяцев), но при этом
SELECTзапрос происходит довольно часто (каждые 20 минут)
Нужно иметь данный фактор ввиду, так как при каждом изменении данных Materialized View нужно обновлять, чтобы подтянуть свежие изменения. И для часто-обновляющихся данных такой способ не подойдет.
Что такое Materialized View? Это результат нашего SELECT запроса который занимает физическое место на нашем диске, тогда как обычный View скорее является алиасом. Соответственно это дает нам возможность использовать наш materialized view как обычную таблицу, на которую можно навесить нужные нам индексы. Но, в отличии от обычной таблицы, мы не можем: удалять, вставлять, изменять данные непосредственно в materialized view. Обновление данных materialized view происходит согласно SELECT запросу командой REFRESH MATERIALIZED VIEW.
Денормализуем наши данные и сохраним их в materialized view:
CREATE MATERIALIZED VIEW users_with_theme_rejects AS
SELECT users.id,
array_agg(DISTINCT main_themes.id) AS main_themes,
array_agg(DISTINCT sub_themes.id) FILTER (WHERE sub_themes.id IS NOT NULL) AS sub_themes,
array_agg(DISTINCT focus.id) FILTER (WHERE focus.id IS NOT NULL) AS focuses
FROM users
INNER JOIN rejected_themes AS rt ON rt.user_id = users.id
INNER JOIN preferences_themes AS main_themes ON main_themes.id = rt.theme_id AND main_themes.level = 0
LEFT JOIN rejected_themes AS rt_sub ON rt_sub.user_id = users.id
LEFT JOIN preferences_themes AS sub_themes ON sub_themes.id = rt_sub.theme_id AND sub_themes.level = 1
LEFT JOIN rejected_themes AS rt_focus ON rt_focus.user_id = users.id
LEFT JOIN preferences_themes AS focus ON focus.id = rt_focus.theme_id AND focus.level = 2
GROUP BY users.id
WITH DATA;Теперь нужно не забыть обновлять наш созданный materialized view при изменении блокировок:
REFRESH MATERIALIZED VIEW users_with_theme_rejects
Далее можно переписать запрос из предыдущего раздела с использованием созданного materialized view:
SELECT id
FROM users_with_theme_rejects
WHERE '{183}' && main_themes AND (sub_themes IS NULL OR '{207}' && sub_themes) AND (focuses IS NULL OR '{260}' && focuses)Выглядит гораздо короче! Что там по производительности?:
Planning Time: 0.065 ms
Execution Time: 0.050 ms
Это намного быстрее чем было раньше :) Но нужно также учитывать что мы теперь тратим время на обновление materialized view, это тоже можно замерить:
[Sidekiq::Extensions::DelayedClass] [30695bed5bfbfaf4b068ae5b] (18.8ms) REFRESH MATERIALIZED VIEW CONCURRENTLY users_with_theme_rejects
итого
Денормализация бывает полезна когда нам нужно упростить SQL запрос и избавиться от большого количества JOIN-ов. Можно использовать materialized view для того чтобы хранить денормализованный вариант наших данных. Однако, нужно помнить что materialized view имеет свои ограничения и использовать его нужно только в тех ситуациях, когда это может дать нам преимущество.