Система рекомендации с помощью SQL
Не всегда для реализации системы рекомендации требуется использовать алгоритмы машинного обучения. Для некоторых простых вариантов достаточно обычных SQL запросов. Например, пользователь на сайте может указывать свои предпочтения и мы можем ранжировать наши данные в соответствии с его предпочтениями.
контекст
- Пользователь на сайте может указать интересующие его темы
- Статьи на сайте также могут принадлежать определенным темам
ER-схема:
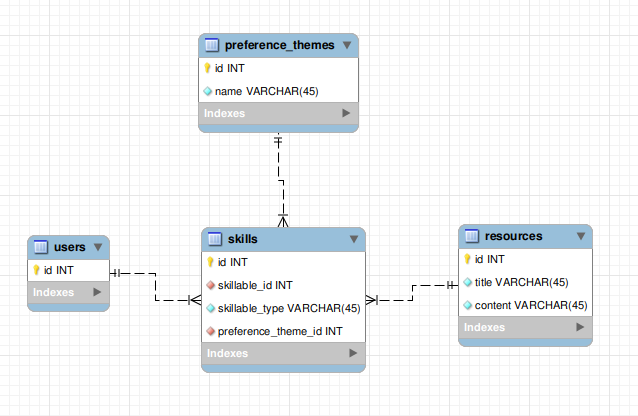
P.S.: не обращайте внимания на VARCHAR(45), это нестабильная работа MySQL Workbench в моей системе. Представьте что это STRING или TEXT.
- users - пользователи
- resources - статьи
- skills - связующая таблица между пользователями/статьями и выбранными темами(preference_themes)
- preference_themes - темы/категории
проблема
Требуется выдавать пользователю статьи упорядочив их по его интересам: чем больше пересечение тем между пользователем и статьей, тем выше должна быть статья в выдаче
решение
Можно использовать ORDER BY где аргументом будет длина пересечения массивов содержащих темы пользователя и статьи. Для реализации этой идеи понадобится расширение для Postgres позволяющее использовать дополнительные операции над массивами - CREATE EXTENSION IF NOT EXISTS intarray;
Добавив это расширение, мы теперь можем использовать следующий SQL запрос:
WITH resources_with_theme_ids AS (
SELECT resources.*,
ARRAY_REMOVE(ARRAY_AGG(DISTINCT skills.preference_theme_id), NULL) AS theme_ids
FROM resources
LEFT OUTER JOIN skills ON skills.skillable_id = resources.id AND skills.skillable_type = 'Resource'
GROUP BY resources.id
)
SELECT id, title, theme_ids
FROM resources_with_theme_ids
ORDER BY CASE
WHEN ARRAY_LENGTH(theme_ids, 1) > 0 THEN
COALESCE(ARRAY_LENGTH(ARRAY[:user_theme_ids]::integer[] & theme_ids::integer[], 1), 0)
ELSE
0
END DESC, id DESC;где :user_theme_ids это темы пользователя.
итого
Мы добавили простое ранжирование статей по предпочтениям пользователя используя обычный SQL запрос. Может быть это не самое быстрое или гибкое решение, но его можно очень быстро реализовать внутри уже имеющегося стека (Postgres/Rails).